|
Use Design Patterns and Mechanisms
|
Use design patterns and mechanisms as suited to the class or capability being designed, and in accordance with project
design guidelines.
Incorporating a pattern and/or mechanism is effectively performing many of the subsequent steps in this task (adding
new classes, operations, attributes, and relationships), but in accordance with the rules defined by the pattern or
mechanism.
Note that patterns and mechanisms are typically incorporated as the design evolves, and not just as the first step in
this task. They are also frequently applied across a set of classes, rather than only to a single class.
|
Create Initial Design Classes
|
Create one or several initial design classes for the analysis class given as input to this task and assign trace
dependencies. The design classes created in this step will be refined, adjusted, split, or merged in subsequent steps
when assigned various design properties-such as operations, methods, and a state machine-that describe how the analysis
class is designed.
Depending on the type of the analysis class (boundary, entity, or control) being designed, there are specific
strategies you can use to create initial design classes.
Boundary classes either represent interfaces to users or to other systems.
Typically, boundary classes that represent interfaces to other systems are modeled as subsystems, because they often
have complex internal behavior. If the interface behavior is simple (perhaps acting as only a pass-through to an
existing API to the external system), you might choose to represent the interface with one or more design classes. If
you choose this route, use a single design class per protocol, interface, or API and note special requirements about
standards you used in the special requirements of the class.
Boundary classes that represent interfaces to users generally follow the rule of one boundary class for each window, or
one for each form, in the user interface. Consequently the responsibilities of the boundary classes can be on a fairly
high-level, and need to be refined and detailed in this step. Additional models or prototypes of the user interface can
be another source of input to be considered in this step.
The design of boundary classes depends on the user interface (UI) development tools available to the project. Using
current technology, it's common that the UI is visually constructed directly in the development tool. This
automatically creates UI classes that need to be related to the design of control and entity classes. If the UI
development environment automatically creates the supporting classes it needs to implement the UI, there is no need to
consider them in design. You design only what the development environment does not create for you.
During analysis, entity classes represent manipulated units of information. They are often passive and persistent, and
might be identified and associated with the analysis mechanism for persistence. The details of designing a
database-based persistence mechanism are covered in Task: Database Design. Performance considerations could force some refactoring of persistent classes, causing changes to the
Design Model that are discussed jointly between the Role: Database Designer and the Role: Designer.
A broader discussion of design issues for persistent classes is presented later under the heading Identify Persistent Classes.
A control object is responsible for managing the flow of a use case and, therefore, coordinates most of its actions;
control objects encapsulate logic that is not particularly related to user interface issues (boundary objects) or to
data engineering issues (entity objects). This logic is sometimes called application logic or business
logic.
Take the following issues into consideration when control classes are designed:
-
Complexity - You can handle uncomplicated controlling or coordinating behavior using boundary or entity
classes. As the complexity of the application grows, however, significant drawbacks to this approach surface, such
as:
-
the use-case coordinating behavior becomes embedded in the UI, making it more difficult to change the system
-
the same UI cannot be used in different use-case realizations without difficulty
-
the UI becomes burdened with additional functionality, degrading its performance
-
the entity objects might become burdened with use-case specific behavior, reducing their generality
To avoid these problems, control classes are introduced to provide behavior related to coordinating
flows-of-events.
-
Change probability - If the probability of changing flows of events is low or the cost is negligible, the
extra expense and complexity of additional control classes might not be justified.
-
Distribution and performance - The need to run parts of the application on different nodes, or in different
process spaces, introduces the need to specialize design model elements. This specialization is often accomplished
by adding control objects and distributing behavior from the boundary and entity classes onto the control classes.
In doing this, the boundary classes migrate toward providing purely UI services, the entity classes move toward
providing purely data services, and the control classes provide the rest.
-
Transaction management - Managing transactions is a classic coordination activity. Without a framework to
handle transaction management, one or more transaction manager classes would have to interact to ensure that
you maintain the integrity of the transactions.
In the latter two cases, if the control class represents a separate thread of control, it might be more appropriate to
use an active class to model the thread of control. In a real-time system, the use of Artifact: Capsules is the preferred modeling approach.
|
Identify Persistent Classes
|
Classes that need to store their state on a permanent medium are referred to as persistent. The need to store their
state might be for permanent recording of class information, for backup in case of system failure, or for exchange of
information. A persistent class might have both persistent and transient instances; labeling a class persistent means
merely that some instances of the class might need to be persistent.
Incorporate design mechanisms corresponding to persistency mechanisms found during analysis. For example, depending on
what is required by the class, the analysis mechanism for persistency might be realized by one of these design
mechanisms:
-
In-memory storage
-
Flash card
-
Binary file
-
Database Management System (DBMS)
Persistent objects might not be derived from entity classes only; persistent objects could also be needed to handle
nonfunctional requirements in general. Examples are persistent objects needed to maintain information relevant to
process control or to maintain state information between transactions.
Identifying persistent classes serves to notify the Role: Database Designer that the class requires special attention to its physical storage characteristics. It also
notifies the Role: Software Architect that the class needs to be persistent and
the Role: Designer responsible for the persistence mechanism that
instances of the class need to be made persistent.
Due to the need for a coordinated persistence strategy, the Role: Database Designer is responsible for mapping persistent classes into the database, using a persistence framework.
If the project is developing a persistence framework, the framework developer will also be responsible for
understanding the persistence requirements of design classes. To provide these people with the information they need,
it's sufficient at this point to indicate that the class is persistent or, more precisely, that the instances of the
class are persistent.
|
Define Class Visibility
|
For each class, determine the class visibility within the package in which it resides. A public class can be
referenced outside of the containing package. A private class (or one whose visibility is implementation)
might only be referenced by classes within the same package.
|
Define Operations
|
To identify operations on design classes:
-
Study the responsibilities of each corresponding analysis class, creating an operation for each responsibility. Use
the description of the responsibility as the initial description of the operation.
-
Study the use-case realizations in the class participates to see how the operations are used by the use-case
realizations. Extend the operations, one use-case realization at the time, refining the operations, their
descriptions, return types, and parameters. Each use-case realization's requirements pertaining to classes are
described textually in the Flow of Events of the use-case realization.
-
Study the Special Requirements use case to be sure that you do not miss implicit requirements on the operation that
might be stated there.
Operations are required to support the messages that appear on sequence diagrams because scripts-temporary message
specifications that have not yet been assigned to operations-describe the behavior the class is expected to perform.
Figure 1 illustrates an example of a sequence diagram.
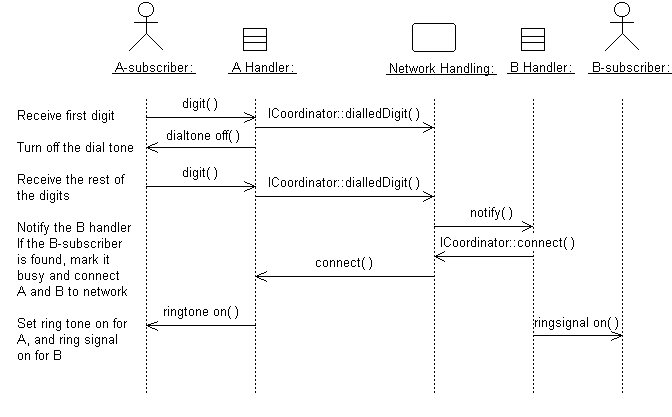
Figure 1: Messages Form the Basis for Identifying Operations
Use-case realizations cannot provide enough information to identify all operations. To find the remaining operations,
consider the following:
-
Is there a way to initialize a new instance of the class, including connecting it to instances of other classes to
which it is associated?
-
Is there a need to test to see if two instances of the class are equal?
-
Is there a need to create a copy of a class instance?
-
Are any operations required on the class by mechanisms that they use? For example, a garbage collection
mechanism might require that an object is able to drop all of its references to all other objects so that any
unused resources can be freed up.
Do not define operations that merely get and set the values of public attributes (see Define Attributes and Define Associations).
Usually these are generated by code-generation facilities and do not need to be defined explicitly.
Use naming conventions for the implementation language when you're naming operations, return types, and parameters and
their types. These are described in the Project-Specific Guidelines.
For each operation, you should define the following:
-
The operation name - keep the name short and descriptive of the result the operation achieves.
-
The names of operations should follow the syntax of the implementation language. Example:
find_location would be acceptable for C++ or Visual Basic, but not for Smalltalk (in which
underscores are not used); a better name for all would be findLocation.
-
Avoid names that imply how the operation is performed. For example, Employee.wages() is better than
Employee.calculateWages(), since the latter implies a calculation is performed. The operation might
simply return a value in a database.
-
The name of an operation should clearly show its purpose. Avoid unspecific names, such as getData,
that are not descriptive about the result they return. Use a name that shows exactly what is expected, such
as getAddress. Better yet, simply let the operation name be the name of the property that is
returned or set. If it has a parameter, it sets the property. If it has no parameter, it gets the property.
Example: the operation address returns the address of a Customer, whereas
address(aString) sets or changes the address of the Customer. The get and set
nature of the operation are implicit from the signature of the operation.
-
Operations that are conceptually the same should have the same name even if different classes define them,
if they are implemented in entirely different ways, or if they have a different number of parameters. An
operation that creates an object, for example, should have the same name in all classes.
-
If operations in several classes have the same signature, the operation must return the same kind of result
appropriate for the receiver object. This is an example of the concept of polymorphism, which says
that different objects should respond to the same message in similar ways. Example: the operation
name should return the name of the object, regardless of how the name is stored or derived.
Following this principle makes the model easier to understand.
-
The return type - The return type should be the class of object that is returned by the operation.
-
A short description - As meaningful as you try to make it, the name of the operation is often only vaguely
useful when trying to understand what the operation does. Give the operation a short description consisting of a
couple of sentences, written from the operation user's perspective.
-
The parameters - For each parameter, create a short descriptive name, decide on its class, and give it a
brief description. As you specify parameters, remember that fewer parameters mean better reusability. A small
number of parameters makes the operation easier to understand and, therefore, there is a higher likelihood of
finding similar operations. You might need to divide an operation with many parameters into several operations. The
operation must be understandable to those who want to use it. The brief description should include:
-
the meaning of the parameters, if not apparent from their names
-
whether the parameter is passed by value or by reference
-
parameters that must have values supplied
-
parameters that can be optional and their default values, if no value is provided
-
valid ranges for parameters, if applicable
-
what is done in the operation
-
what by reference parameters are changed by the operation
Once you've defined the operations, complete the sequence diagrams with information about what operations are invoked
for each message.
Refer to the section titled Guideline: Design Class for more information.
For each operation, identify the export visibility of the operation from these choices:
-
Public - the operation is visible to model elements other than the class itself.
-
Implementation - the operation is visible only within the class itself.
-
Protected - the operation is visible only to the class itself, to its subclasses, or to friends of
the class (language-dependent).
-
Private - the operation is visible only to the class itself and to friends of the class
Choose the most restricted visibility possible that can still accomplish the objectives of the operation. To do this,
look at the sequence diagrams and, for each message, determine whether the message is coming from a class outside of
the receiver's package (requires public visibility), from inside of the package (requires implementation
visibility), from a subclass (requires protected visibility), or from the class itself or a friend (requires
private visibility).
For the most part, operations are instance operations; that is, they are performed on instances of the class. In some
cases, however, an operation applies to all instances of the class and, therefore, is a class-scope operation.
The class operation receiver is actually an instance of a metaclass-the description of the class itself-rather
than any specific instance of the class. Examples of class operations include messages that create (instantiate) new
instances, which return all Instances of a class.
The operation string is underlined to denote a class-scope operation.
|
Define Methods
|
A method specifies the implementation of an operation. In many cases where the behavior required by the operation is
sufficiently defined by the operation name, description, and parameters, methods are implemented directly in the
programming language. Where the implementation of an operation requires the use of a specific algorithm or more
information than is presented in the operation's description, a separate method description is required. The
method describes how the operation works, not just what it does.
The method should discuss how to do the following:
-
operations will be implemented
-
attributes will be implemented and used to implement operations
-
relationships will be implemented and used to implement operations
The requirements will vary from case to case, however, the method specifications for a class should always state:
-
what will be done according to the requirements
-
what other objects and their operations will be used
More specific requirements might concern:
-
how parameters will be implemented
-
what, if any, special algorithms will be used
Sequence diagrams are an important source for this. From these it's clear what operations will be used in other objects
when an operation is performed. A specification of what operations will be used in other objects is necessary for the
full implementation of an operation. The production of a complete method specification, therefore, requires that you
identify the operations for the objects involved and inspect the corresponding sequence diagrams.
|
Define States
|
For some operations, the behavior of the operation depends upon the state the receiver object is in. A state machine is
a tool that describes the states an object can assume and the events that cause the object to move from one state to
another (see Technique:
Statechart Diagram). State machines are most useful for describing active classes. Using state machines is
particularly important for defining the behavior of Artifact: Capsules.
An example of a simple state machine is shown in Figure 2.
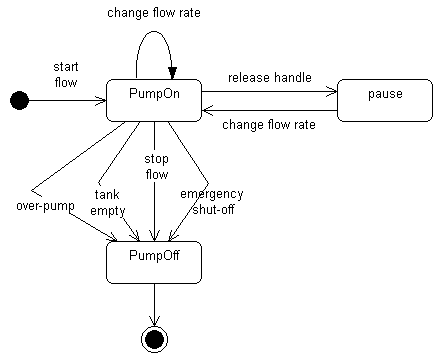
Figure 2: A Simple Statechart Diagram for a Fuel Dispenser
Each state transition event can be associated with an operation. Depending on the object's state, the operation might
have a different behavior and the transition events describe how this occurs.
The method description for the associated operation should be updated with the state-specific information,
indicating for each relevant state what the operation should do. States are often represented using attributes;
the statechart diagrams serve as input into the attribute identification step.
For more information, see Guideline: Statechart Diagram.
|
Define Attributes
|
During the definition of methods and the identification of states, attributes needed by the class to
carry out its operations are identified. Attributes provide information storage for the class instance and are often
used to represent the state of the class instance. Any information the class itself maintains is done through its
attributes. For each attribute, define:
-
its name, which should follow the naming conventions of both the implementation language and the project
-
its type, which will be an elementary data type supported by the implementation language
-
its default or initial value, to which it is initialized when new instances of the class are created
-
its visibility, which will take one of the following values:
-
Public: the attribute is visible both inside and outside of the package containing the class
-
Protected: the attribute is visible only to the class itself, to its subclasses, or to friends of
the class (language-dependent)
-
Private: the attribute is only visible to the class itself and to friends of the class
-
Implementation: the attribute is visible only to the class itself
-
persistent classes, whether the attribute is persistent (the default) or transient. Even though the class
itself might be persistent, not all attributes of the class need to be persistent
Check to make sure all attributes are needed. Attributes should be justified-it's easy for attributes to be added early
in the process and survive long after they're no longer needed due to shortsightedness. Extra attributes, multiplied by
thousands or millions of instances, can have a detrimental effect on the performance and storage requirements of a
system.
Refer to the section titled Attributes in Guideline: Design Class for more information on attributes.
|
Define Dependencies
|
For each case where the communication between objects is required, ask these questions:
-
Is the reference to the receiver passed as a parameter to the operation? If so, establish a dependency
between the sender and receiver classes in a class diagram containing the two classes. Also, if the
communication diagram format for interactions is used, then qualify the link visibility and set it to
parameter.
-
Is the receiver a global? If so, establish a dependency between the sender and receiver classes in a class
diagram containing the two classes. Also, if the communication diagram format for interactions is used,
qualify the link visibility and set it to global.
-
Is the receiver a temporary object created and destroyed during the operation itself? If so, establish a
dependency between the sender and receiver classes in a class diagram containing the two classes. Also, if
the communication diagram format for interactions is used, qualify the link visibility and set it to
local.
Note that links modeled this way are transient links, existing only for a limited duration in the specific context of
the collaboration-in that sense, they are instances of the association role in the collaboration. However, the
relationship in a class model (that is, independent of context) should be a dependency, as previously stated. As [RUM98] states, in the definition of transient link: "It is possible to model
all such links as associations, but then the conditions on the associations must be stated very broadly, and they lose
much of their precision in constraining combinations of objects." In this situation, the modeling of a dependency is
less important than the modeling of the relationship in the collaboration, because the dependency does not describe the
relationship completely; only that it exists.
|
Define Associations
|
Associations provide the mechanism for objects to communicate with one another. They provide objects with a conduit
along which messages can flow. They also document the dependencies between classes, highlighting that changes in one
class could be felt among many other classes.
Examine the method descriptions for each operation to understand how instances of the class communicate and
collaborate with other objects. To send a message to another object, an object must have a reference to the receiver of
the message. A communication diagram (an alternative representation of a sequence diagram) will show object
communication in terms of links, as illustrated in Figure 3.
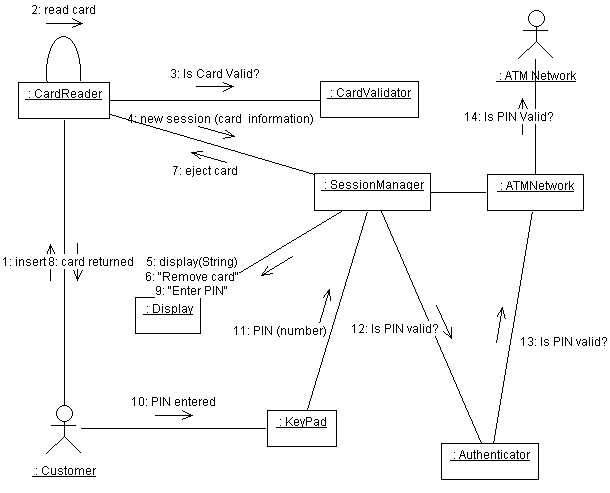
Figure 3: An Example of a Communication Diagram
The remaining messages use either association or aggregation to specify the relationship between
instances of two classes that communicate. See Guideline: Association and Guideline: Aggregation for information on choosing the appropriate representation.
For both of these associations, set the link visibility to field in communication diagrams. Other tasks include:
-
Establish the navigability of associations and aggregations. You can do this by considering what navigabilities are
required on their link instantiations in the interaction diagrams. Because navigability is true by default,
you only need to find associations (and aggregations) where all opposite link roles of all objects of a class in
the association do not require navigability. In those cases, set the navigability to false on the role of
the class.
-
If there are attributes on the association itself (represented by association classes), create a design class to
represent the association class, with the appropriate attributes. Interpose this class between the other two
classes, and establish associations with appropriate multiplicity between the association class and the other two
classes.
-
Specify whether association ends should be ordered or not; this is the case when the objects
associated with an object at the other end of the association have an ordering that must be preserved.
-
If the associated (or aggregated) class is only referenced by the current class, consider whether the class should
be nested. Advantages of nesting classes include faster messaging and a simpler design model. Disadvantages include
having the space for the nested class statically allocated regardless of whether there are instances of the nested
class, a lack of object identity separate from the enclosing class, or an inability to reference nested class
instances from outside of the enclosing class.
Associations and aggregations are best defined in a class diagram that depicts the associated classes. The class
diagram should be owned by the package that contains the associated classes. Figure 4 illustrates an example of
a class diagram, depicting associations and aggregations.
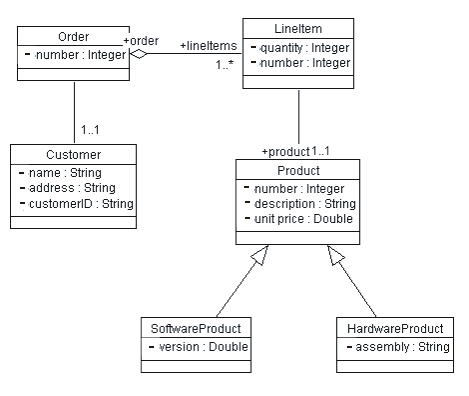
Figure 4: Example of a Class Diagram showing Associations, Aggregations, and Generalizations between Classes
Subscribe-associations between analysis classes are used to identify event dependencies between classes. In the
Design Model you must handle these event dependencies explicitly, either by using available event-handler frameworks or
by designing and building your own event-handler framework. In some programming languages-such as Visual Basic-this is
straightforward; you declare, raise, and handle the corresponding events. In other languages, you might have to use
some additional library of reusable functions to handle subscriptions and events. If the functionality can't be
purchased, it will need to be designed and built. See also Guideline: Subscribe-Association.
|
Define Internal Structure
|
Some classes may represent complex abstractions and have a complex structure. While modeling a class, the designer may
want to represent its internal participating elements and their relationships, to make sure that the implementer will
accordingly implement the collaborations happening inside that class.
In UML 2.0, classes are defined as structured
classes, with the capability to have a internal structure and ports. Then, classes may be decomposed into
collections of connected parts that may be further decomposed in turn. A class may be encapsulated by forcing
communications from outside to pass through ports obeying declared interfaces.
When you find a complex class with complex structure, create a composite structure diagram for that class. Model the
parts that will perform the roles for that class behavior. Establish how parts are 'wired' together by using
connectors. Make use of ports with declared interfaces if you want to allow different clients of that class access
specific portions of behavior offered by that class. Also make use of ports to fully isolate the internal parts of that
class from its environment.
For more information on this topic and examples on composite structure diagram, see Concept: Structured Class.
|
Define Generalizations
|
Classes might be organized into a generalization hierarchy to reflect common behavior and common structure. A common
superclass can be defined, from which subclasses can inherit both behavior and structure. Generalization
is a notational convenience that allows you to define common structure and behavior in one place, and to reuse it where
you find repeated behavior and structure. Refer to Guideline: Generalization for more information on generalization relationships.
When you find a generalization, create a common superclass to contain the common attributes, associations,
aggregations, and operations. Remove the common behavior from the classes that will become subclasses of the common
superclass. Define a generalization relationship from the subclass to the superclass.
|
Resolve Use-Case Collisions
|
The purpose of this step is to prevent concurrency conflicts caused when two or more use cases could potentially access
instances of the design class simultaneously, in possibly inconsistent ways.
One of the difficulties with proceeding use-case-by-use-case through the design process is that two or more use cases
could attempt to invoke operations simultaneously on design objects in potentially conflicting ways. In these cases,
concurrency conflicts must be identified and resolved explicitly.
If synchronous messaging is used, executing an operation will block subsequent calls to the objects until the operation
completes. Synchronous messaging implies a first-come, first-served ordering to message processing. This might resolve
the concurrency conflict, especially in cases where all messages have the same priority or where every message runs
within the same execution thread. In cases where an object might be accessed by different threads of execution
(represented by active classes), explicit mechanisms must be used to prevent or resolve the concurrency conflict.
In real-time systems where threads are represented by Artifact: Capsules, this problem still has to be solved for multiple concurrent access to passive objects, whereas the
capsules themselves provide a queuing mechanism and enforce run-to-completion semantics to handle concurrent access. A
recommended solution is to encapsulate passive objects within capsules, which avoids the problem of concurrent access
through the semantics of the capsule itself.
It might be possible for different operations on the same object to be invoked simultaneously by different threads of
execution without a concurrency conflict; both the name and address of a customer could be modified concurrently
without conflict. It's only when two different threads of execution attempt to modify the same property of the object
that a conflict occurs.
For each object that might be accessed concurrently by different threads of execution, identify the code sections that
must be protected from simultaneous access. Early in the Elaboration phase, identification of specific code segments
will be impossible; operations that must be protected will suffice. Next, select or design appropriate access control
mechanisms to prevent conflicting simultaneous access. Examples of these mechanisms include message queuing to
serialize access, use of semaphores or tokens to allow access only to one thread at a time, or other variants of
locking mechanisms. The choice of mechanism tends to be highly implementation-dependent, and typically varies with the
programming language and operating environment. See the Project-Specific Guidelines for guidance on selecting concurrency
mechanisms.
|
Handle Nonfunctional Requirements in General
|
The Design Classes are refined to handle general, nonfunctional requirements. Important input to this step include the
nonfunctional requirements on an analysis class that might already be stated in its special requirements and
responsibilities. Such requirements are often specified in terms of what architectural (analysis) mechanisms are needed
to realize the class; in this step, the class is then refined to incorporate the design mechanisms corresponding to
these analysis mechanisms.
The available design mechanisms are identified and characterized by the software architect. For each design mechanism
needed, qualify as many characteristics as possible, giving ranges where appropriate. Refer to Task: Identify Design Mechanisms, Concept: Analysis Mechanisms, and Concept: Design and Implementation Mechanisms for more information on design
mechanisms.
There can be several general design guidelines and mechanisms that need to be taken into consideration when classes are
designed, such as how to:
-
use existing products and components
-
adapt to the programming language
-
distribute objects
-
achieve acceptable performance
-
achieve certain security levels
-
handle errors
|
Evaluate Your Results
|
Check the design model at this stage to verify that your work is headed in the right direction. There is no need to
review the model in detail, but you should consider the following checklists:
|
|
